
Siapedia
I put Wikipedia on the Sia network. Try it at siapedia.org.
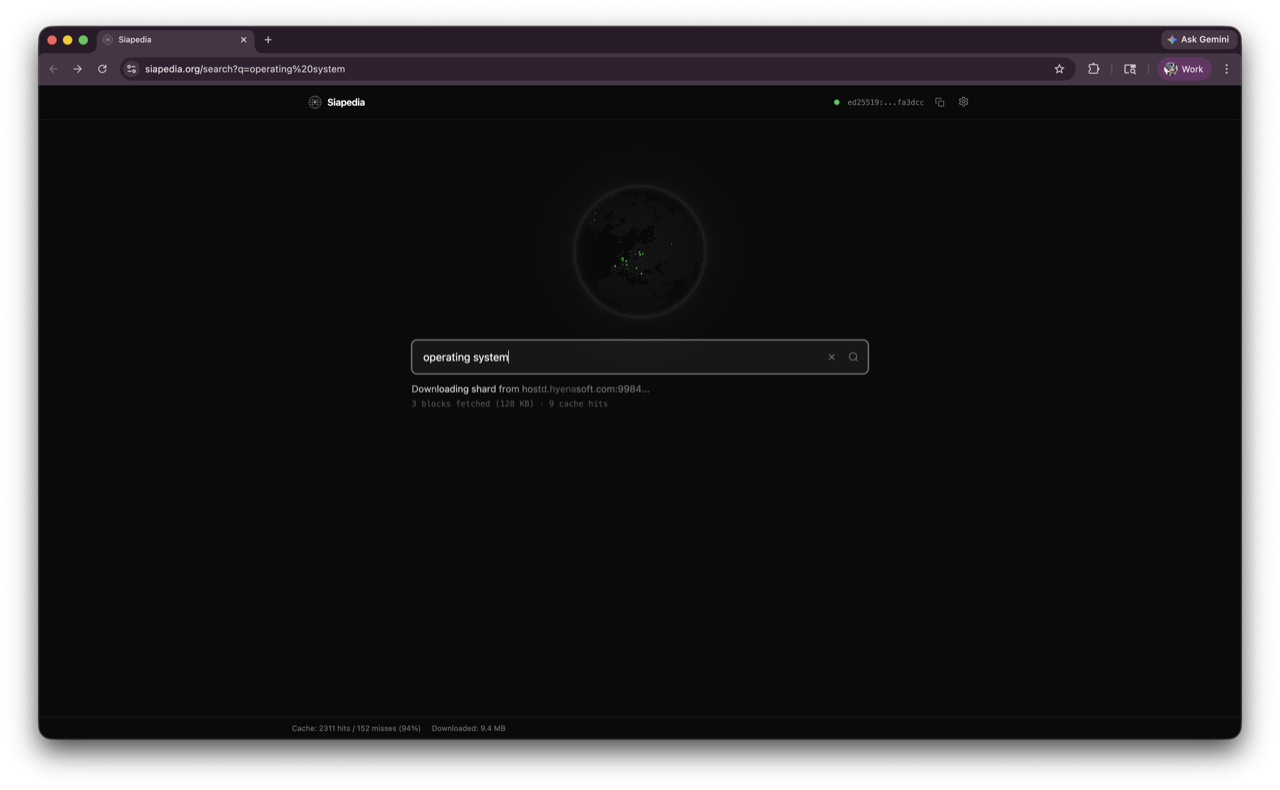
I took the Simple English Wikipedia XML dump, parsed every article, inserted them into a SQLite database with an FTS5 search index, and uploaded the resulting 1.5 GB file to the Sia network using the Sia Storage SDK. The file gets encrypted, erasure-coded, and distributed as slabs and shards across dozens of independent Sia hosts.
SQLite databases are read in pages — small fixed-size blocks. You don't need to download the whole file to run a query. You just need the pages that contain the data you're looking for. A search index lookup or an article fetch typically reads 3-5 pages, about 200 KB total out of 1.5 GB.
The browser runs SQLite via WebAssembly with a custom virtual filesystem. Instead of reading pages from disk, it reads them from Sia hosts using range requests. SQLite asks for a page, the VFS fetches that range from the network, and SQLite gets its data.
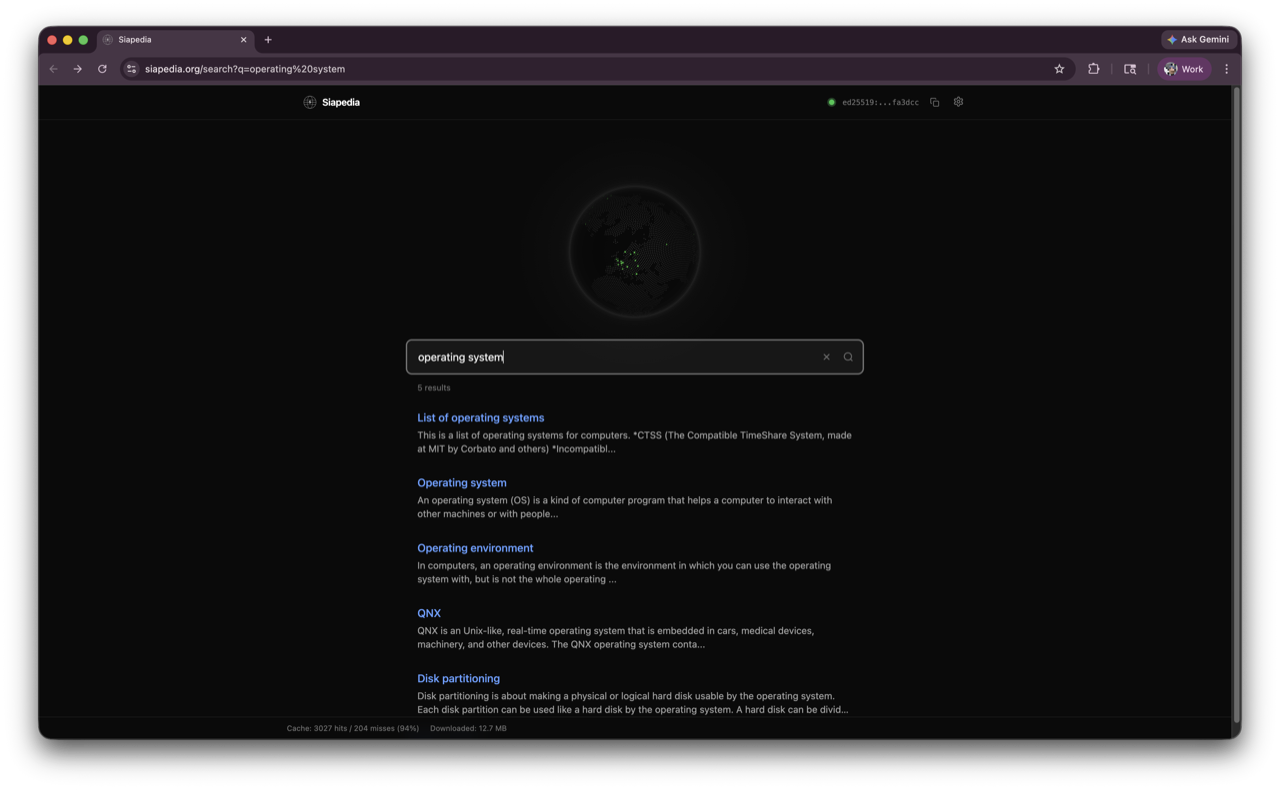
Pages are cached at the block level. The first time you read a block, it comes from the Sia network — you can see the individual shards arriving from different hosts as they come in. After that, the block is cached in memory and in IndexedDB. Subsequent reads that hit the same block are instant. IndexedDB persists across page reloads, so a warm cache means articles load almost immediately on repeat visits. Related data tends to be stored near each other in the database, so reading one article often warms the cache for nearby articles too.
For now it's just Simple English Wikipedia, text only — no images. But the same approach could scale to all of Wikipedia.
Build your own experiments with the Sia Storage SDK, available on npm as @siafoundation/sia-storage. Reach out with any questions here.